Idag er der flere meget elegante systemer, der hjælper med at implementere et DSL til en given opgave. I artiklen beskriver Jan Schoubo, hvordan han har anvendt værktøjet JavaCC til at definere et DSL som letter udviklingen af kombinerede Google App Engine / Android løsninger.
Ved hjælp af en model-beskrivelses-fil og en generator produceres en god del af den kedelige kode, så udvikleren kan koncentrere mig om forretningslogik og grafik.
Formål med generatoren
Både Google App Engine og Android løsninger er kendetegnede ved at der er nogle bestemte konventioner (Patterns) for kodens opbygning, som du ikke er direkte tvunget til at overholde, men som har stor betydning for løsningens kvalitet. Man kan kalde disse konventioner Best Practice, men i nogle tilfælde er de ikke blot et gode, men en decideret nødvendighed.
For at sikre at mine løsninger overholder disse konventioner – uden at jeg skal spekulere for meget på dem undervejs – har jeg skrevet en generator, som bygger de klasser og andre elementer, som jeg alligevel altid ville tilstræbe at lave på en bestemt måde. Samtidig slipper jeg for en del rugbrødsprogrammering og kan koncentrere mig om de interessante dele – forretningslogikken og grafikken.
Ideen med en generator ligger lige for.
- For det første bruger både Google Web Toolkit (GWT) og Android Development Toolkit (ADT) generatorer i forvejen – GWT til at producere JavaScript ud fra Java kode og ADT til at producere R.java ud fra diverse XML Resource filer.
Der er iøvrigt i ingen af tilfældene tale om egentlige DSL’er da JavaScript-genereringen er baseret på Java-kode som må siges at være et General Purpose Language (GPL), og R.java-genereringen er baseret på XML filer, som desuden kan siges ikke at være tilstrækkeligt udtruksfulde til at udgøre egentlige DSL’er.
- For det andet vil en generator have muligheden for at sikre en effektiv kode. En tidlig prototype jeg lavede til Android-delen brugte Java Reflection over Annotations, men fordi logikken skulle med ud i selve applikationen, blev applikationen både langsommere og fyldte mere. Med en generator bliver den samme infrastruktur-logik udført på oversættelsestidspunktet, og da den typisk ikke behøver at være dynamisk, så bliver den overstået under bygningen af applikationen og mærkes derfor ikke af brugeren.
- For det tredie skrev jeg mine første generatorer for over 35 år siden – en SPSS data-statement generator, og en pendant til Hibernate for Pascal og FORTRAN. Så det er et område jeg betragter som min hjemmebane.
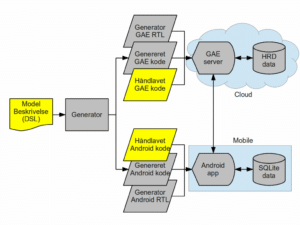
Generatoren læser en fil med model-beskrivelse for projektet i en DSL syntaks opfundet til lejligheden.
Et kort eksempel – en tænkt applikation til beregning af vagtplaner:
language en,da;
model DutyRoster
doc "Duty Roster|da:Vagtplan",
"Calculate duty rosters|da:Beregn vagtplaner"
option
ANDROID (
"permission:INTERNET,ACCESS_NETWORK_STATE",
"package:dk.schoubo.dutyroster.android",
"sdk:11,15"
),
GWT (
"package:dk.schoubo.dutyroster.gae"
)
include libGenerator "dk.schoubo.generator.library"
{
class Address
doc "Address|da:Adresse",
"Addresses|da:Adresser",
"Address and contact information" +
"|da:Adresse- og kontakt-information"
{
field String name
doc "Name|da:Navn", "Full name|da:Fulde navn"
width 12.0;
field String email
doc "Email|da:Email", "Email|da:Email adresse"
width 12.0 option HIDEINLIST;
}
class Customer
doc "Customer|da:Kunde",
"Customers|da:Kunder",
"A customer ordering a duty roster" +
"|da:En kunde der har bestilt en vagtplan"
option TABLE, USE ("Timestamped")
{
field String customerName
doc "Customer Name|da:Kundenavn",
"Name of the customer|da:Navn på kunden"
width 12.0 option KEY;
field Addressable company
doc "Company|da:Firma",
"Company information|da:Kundeoplysninger";
field Plan plans
doc "Plans|da:Planer",
"Duty rosters for this customer" +
"|da:Vagtplaner for denne kunder"
option SET;
view form;
view list;
}
rest PutCustomer doc "Save customer|da:Gem kunde"
option POST, JSONP, XML, JSON
in customer.CustomerXMLDTO
out String;
view client Login
doc "Login|da:Log ind", ""
option ANDROIDGUI, ISPOPUP("Boolean")
{
navigation Administration;
field EditText Username;
field EditText Password;
field Button Login;
field Button ForgotPassword;
async LoginWithPassword option PROGRESSBUSY;
}
....
}
}
Eks. 1 – DSL-fil med model: dutyroster.sr-model
Som man kan se af eksemplet, så er sproget temmelig udtryktsfuldt, men samtidig kompakt – hvilket kendetegner DSL’er. Det vil føre for vidt at komme ind på alle funktioner, men jeg skal nævne at det er vokset i takt med de krav opgaverne stillede, og at det er temmelig banalt at tilføje en ny konstruktion – i hvert fald hvad angår syntaksen og DSL fortolkningen. Hvordan genereringen så skal ændres for at udnytte en ny konstruktion – det er en anden snak 🙂
Et DSL vil altid være en afvejning af fordele og ulemper – tilsat en vis portion smag og behag.
Konstruktionen:
ANDROID ("permission:INTERNET,ACCESS_NETWORK_STATE",
"package:dk.schoubo.dutyroster.android",...)
kunne f.eks. sagtens være lagt i strammere rammer ved at lade parametrene være en del af syntaksen. Så skulle den måske have set sådan ud:
ANDROID permission [INTERNET,ACCESS_NETWORK_STATE], package dk.schoubo.dutyroster.android,...
Men det ville have betydet flere reserverede ord, som så ikke kunne bruges til navne på typer eller felter.
Resten af artiklen er delt i to dele. Første del handler om selve generatoren og anden del handler om strukturen i den kode der bliver genereret.
Del 1: Generatoren
Generatoren er skrevet i JavaCC og Java Tree Builder. JavaCC er en parser generator med leksikalsk analyse a.la. yacc og lex eller ANTLR. JavaCC blev oprindeligt skrevet af Sun Microsystems, senere videreudviklet af Metamata og WebGain, og i 2002 givet til Open Source.
Java Tree Builder (JTB) er en lille overbygning til generering af et Abstract Syntax Tree (AST) der understøtter Visitor Pattern. JTB stammer fra Purdue University og er ligeledes Open Source. Begge værktøjerne er understøttet af Eclipse Plug-in for JavaCC.
Generatoren er skrevet i JavaCC og Java Tree Builder. JavaCC er en parser generator med leksikalsk analyse a.la. yacc og lex eller ANTLR. JavaCC blev oprindeligt skrevet af Sun Microsystems, senere videreudviklet af Metamata og WebGain, og i 2002 givet til Open Source.
Java Tree Builder (JTB) er en lille overbygning til generering af et Abstract Syntax Tree (AST) der understøtter Visitor Pattern. JTB stammer fra Purdue University og er ligeledes Open Source. Begge værktøjerne er understøttet af Eclipse Plug-in for JavaCC.
DSL til JavaCC
JavaCC generere en parser på grundlag af en Backus-Naur-lignende beskrivelse i – gæt engang – en DSL. Den består af en stribe definitioner, som beskriver hvordan generatoren forventer at en model-beskrivelsen ser ud.
Terminaler – reserverede ord eller tegn – hedder TOKENs.
TOKEN:
{
<COMMA: "," > |
<PERIOD: "." > |
:
<SEMICOLON: ";" >
}
TOKEN:
{
<INTEGER_LITERAL: ["0"-"9"] (["0"-"9"])*>
}
TOKEN [IGNORE_CASE]:
{
<LANGUAGE: "language" ("s")? > |
<MODEL: "model"> |
<FIELD: "field"> |
<ASYNC: "async" ("hronous")? > |
:
}
Eks. 2 – JavaCC TOKEN eksempel
Af TOKEN-beskrivelsen kan man se at ”language” også kan skrives ”LANGUAGE” eller ”Languages”. Men i koden der skal håndtere denne frase optræder det altid som ”language”.
Konstruktioner beskrives blot ved deres navn:
void ClassFieldClause() : { }
{
<FIELD> Identifier() Identifier()
(
DocClause() | OptionClause() | FieldWidthClause()
)* ";"
}
Eks. 3 – JavaCC Production eksempel (fleksibel)
Her kan man se at en felt-beskrivelse består af det reserverede ord ”field” fulgt af to Identifiers og derefter et antal DocClause-, OptionClause- og FieldWidthClause-fraser i vilkårlig rækkefølge fulgt af semikolon. Jeg har valgt ikke at have restriktioner på antal og rækkefølge – optræder der f.eks. flere ”width”-fraser, er det altid den sidste der gælder. Men man kunne også have valgt en mere stringent syntaks, hvor der skulle netop en af hver af disse fraser til, og altid i samme rækkefølge – så ville JavaCC syntaksen have set sådan her ud:
void ClassFieldClause() : { }
{
<FIELD> Identifier() Identifier()
DocClause() OptionClause() FieldWidthClause()
";"
}
Eks. 4 – JavaCC Production eksempel (stringent)
Eclipse Plug-in til JavaCC sørger for automatisk at kalde JavaCC til at generere en parser svarende på syntaksen. Er JTB brugt, kaldes den først.
JTB Visitor-klassen
Resten af DSL-håndteringen består så blot i at udfylde en Visitor-klasse, hvor der skal være en metode for hver produktion i JavaCC syntaksen. Når den genererede parser læser en model-beskrivelse, kalder den de pågældende metoder efter tur, med parametre der giver adgang til de fraser eller del-elementer produktionen består af.
Metoden kan så se ud som følger:
@Override
public ResClient visit(final ClassFieldClause n)
{
ResField res = new ResField();
ResString stype = (ResString)n.identifier.accept(this);
res.setType(stype.toString());
ResString sname = (ResString)n.identifier1.accept(this);
res.setName(sname.toString());
for (INode nodex : n.nodeListOptional.nodes)
{
ResClient node = nodex.accept(this);
if (node instanceof ResDoc)
{
res.addDoc((ResDoc)node);
}
else if (node instanceof ResOptions)
{
res.addAllOptions((ResOptions)node);
}
else
throw new
throw new RuntimeException(
"node should be ResDoc or ResOptions," +
" but was "+node.getClass().getName());
}
return res;
}
Eks. 5 – JTB Visitor eksempel
I metoden behandler man de læste elementer – f.eks. de to Identifiers, som er hhv. typen og navnet på feltet – i min generator skal de blot gemmes i en intern domæne-model der er implementeret som en simpel POJO Java-struktur.
Denne interne domæne-model kan jeg derefter checke for semantiske fejl – ting der er syntaktisk korrekte, men som ikke giver mening – f.eks. et feltnavn der bliver gentaget i den samme klasse eller på det samme skærmbillede.
Hvis kontrollen siger god for modellen, så bruges den af generatoren som basis for at generere kode.
Del 2: Den genererede kode
Hvad bliver genereret? Rigtig mange småfiler.
Mange kildetekster
Et af problemerne med TP-lignende systemer som GAE/GWT og Android er de mange kildetekster, der skal hænge sammen på forskellige vis. For eksempel nævner man i en Android Layout XML Resource-fil et navn på en streng, som så har værdien stående i en String XML Resource fil. Og det er det samme navn man kan referere i Java-koden, via den R.java-fil Android genererer.
Ved at generere så meget som muligt, kan jeg minimere denne forvirring.
Mange ”listenere” med tilhørende klasser
Meget af logikken i GAE/GWT og Android er baseret på et Listener Pattern, hvor man dels skal huske at sætte listeneren på det pågældende objekt, dels skal skrive den tilhørende metode.
Et eksempel fra Android kunne være:
buttonNewTask = (Button) findViewById(R.id.buttonNewTask);
buttonNewTask.setOnClickListener(this);
buttonNewDate = (Button) findViewById(R.id.buttonNewDate);
buttonNewDate.setOnClickListener(this);
:
@Override
public void onClick(final View v)
{
switch (v.getId())
{
case R.id.buttonNewTask:
String taskName = edittextTaskName.getText().toString();
:
break;
case R.id.buttonNewDate:
String taskDate = edittextTaskDate.getText().toString();
:
break;
}
}
Eks. 6 – Android kode (uden generator)
Da der kun kan være een listener-metode af den pågældende type på klassen, skal den indeholde logik (typisk switch) for at udføre den kode der hører til det rigtige UI-element – Button i dette tilfælde.
Den kode jeg genererer pakker alt dette væk, og instantierer i stedet en Activity Delegate med et interface der indeholder en onClickButtonNewTask og en onClickButtonNewDate metode – så skal man blot skrive en klasse der opfylder dette interface, og man får hjælp fra Eclipse til at huske at få alle metoder med.
@Override
public void onClickButtonNewTask(
final View view, final ActionPayload payload)
{
String taskName = edittextTaskName.getText().toString();
:
}
@Override
public void onClickButtonNewDate(
final View view, final ActionPayload payload)
{
String taskDate = edittextTaskDate.getText().toString();
:
}
Eks. 7 – Android kode (med generator)
Flere repræsentationer af de samme entiteter
Et andet problem opstår hvis man gerne vil bruge forskellige teknologier for den samme datamodel:
- JDO som interface til Googles High Replication Datastore på server-siden
- JAXB og JAX-RS (Jersey) til kommunikation med Android
- enkle POJO klasser til kommunikation med GWT klienter
- JDBC som interface til SQLite på Android.
Det viser sig nemlig at f.eks. JDO og JAXB i praksis ikke kan anvende de samme klasser, da visse datatyper (navnlig håndteringen af master-detail) skurrer fælt mellem disse teknologier.
Men med en generator bag er det en smal sag at generere flere versioner af den samme entitet – en med et JDO-venligt format, en med JAXB, en som POJO og en med rutiner til JDBC håndtering indbygget. Og fordi de er genereret automatisk er der intet problem i at tilføje eller modificere felter og typer – Eclipse vil øjeblikkeligt vise hvor man skal rette sin egen kode.
Genereret versus håndlavet
Et klassisk problem, der har eksisteret siden 4GL var populært i 80’erne, er håndteringen af den kode der trods alt skal skrives i hånden. Med moderne Java er det heldigvis nemt at adskille dette. Et mønster jeg ofte anvender er Delegate Pattern. For eksempel genererer jeg en Android Activity der uddelegerer de enkelte handlinger til en delegate, defineret ved et interface, og det er så den klasse – og kun den klasse – der skal skrives i hånden.
For filer hvor dette ikke kan lade sig gøre, genererer jeg en prototype, hvis der ikke er nogen fil i forvejen, ellers ikke. Det gælder f.eks. Layout XML Resource filer. Her får man også hjælp fra Eclipse, for hvis man for eksempel tilføjer et nyt felt til et skærmbillede, så vil generatoren ikke tilføje den når Layout filen allerede findes, men da felter refereres i en GUI-håndteringsklasse som bliver genereret igen, så skal Eclipse nok fortælle at man mangler et UI element i Layout-filen.
Nedenfor er en kort liste over de vigtigste elementer generatoren kan levere.
Google App Engine
- JDO klasser
- JAXB klasser
- Data Transfer Object klasser til GWT
- Databundne GWT skærmbilleder (1 eller n records) og Ikke-databundne GWT skærmbilleder
-
- Felttyper: Tal, Beløb, Dato, Billede (evt. med Upload knap og Browser funktion)
-
- Data-funktioner: Ny, Ret, Slet, Op, Ned
-
- Forretnings-funktioner: Start betaling, Generer dokumentation, …
-
- Diverse: Hjælp, Hjem, Logud
-
- Navigation mellem skærmbilleder
- REST stubbe (JAX-RS med Jersey)
- Hjælp
-
- Datadiagram med aktuel placering
-
- Feltbeskrivelser
- I18N
-
- Felt og tabel dokumentation – komplet online data dictionary
-
- Andre tekster – vilkårligt mange sprog, oversættelser samlet i en fil.
- Android
-
- SQLite JDBC klasser
-
- Activity klasser
-
- Activity delegate prototyper
-
-
- Med tilhørende interfaces
-
-
- Layout prototype
-
-
- Indeholder alle UI-elementer, med default Styles.
-
-
- GUI håndtering
-
-
- Står for al instantiering af UI elementer
-
-
- Forretningslogik prototype
-
- Navigation mellem skærmbilleder
Resultat
Hvad har jeg fået ud af generatoren?
For det første har jeg gjort afstanden fra en ”serviet-skitse” af en applikation til en prototype ganske kort – uden at erstatte skitsen med en grafisk design applikation – blyant og papir er stadig den førende teknologi til at nedbryde afstanden mellem bruger og udvikler.
Model-beskrivelsen er ikke kun tilpasset den kode der skal genereres, men også designet så den nemt kan aflæses fra skitsen.
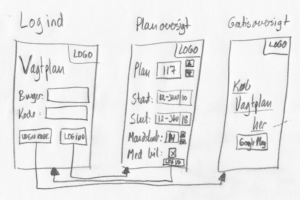
For det andet har jeg gjort det nemmere at skrive kode til events – både at huske at få dem alle med, og at kunne flytte dem fra en GUI-element type til en anden.
Og endelig slipper jeg for at skrive den kedelige skabelon-kode, som skal laves ens i alle projekter. I de projekter jeg foreløbig har lavet, anslår jeg at omkring halvdelen af koden nu er enten genereret eller tilhører generatorens Run Time Library.
Fremtiden
Projektet er ikke tænkt som et generelt værktøj, og indeholder derfor ikke understøttelse af alle tænkelige Android og GAE funktioner – langtfra. Jeg har tilføjet funktioner i takt med at de applikationer jeg skulle lave fik brug for dem.
Undervejs er jeg også blevet klogere, så visse dele bør nok refaktoreres. Særlig GWT-delen kan ændres, så den ligner Android-delen mere – det er ikke nødvendigt for funktionaliteten, men det vil gøre værktøjet lidt mere strømlinet.
På Android-delen vil jeg også udbygge de funktioner, der understøtter Styles og forskellige layout-størrelser – når jeg nu har anskaffet en Google Nexus-7 at prøve det af på.
Endelig kunne jeg også overveje at lade generatoren tilføje nye elementer til eksisterende XML Resource-filer – det kræver at den skal læse den eksisterende fil, og indsætte manglende UI-elementer sidst i XML strukturen.
Men det er ideer jeg tager op når næste projekt skal i gang…
Hvordan kan du lære mere?
En rigtig god ide vil være at tage mit DSL kursus – som du selvfølgelig kan få hos Lund og Bendsen: LB2931 – Domain-Specific Languages (2 dage). Her kommer vi ind på mange af de emner der er beskrevet i artiklen.
Hvis du er interesseret i Google App Engine eller Android er der også flere kurser du med fordel kan overveje
Referencer
JavaCC
Tom Copeland: Generating Parsers with JavaCC, ISBN 976-221438
JTB
https://www.cs.ucla.edu/~palsberg/jtb/
DSL
Standardværket er Martin Fowler: Domain-Specific Languages, ISBN 978-1481218580
Ny bog er Markus Völter: DSL Engineering, ISBN 978-0321712943
Android og Google App Engine
https://developer.android.com/develop/index.html
https://developers.google.com/appengine/docs/java/overview
Lars Vogel har også nogle glimrende tutorials for begyndere: http://www.vogella.com